According to The Financial Times, OpenAI claims to have evidence suggesting that DeepSeek utilized its models through a technique known as “distillation” to train their own AI systems. This process implies that DeepSeek submitted numerous queries to OpenAI’s models, collected the responses, and used this data to enhance their own models.
Distillation is a well-established method in AI model development. It involves using the outputs of a more advanced “teacher” model to train a smaller, more efficient “student” model. The goal is for the student model to achieve performance levels comparable to the teacher while requiring fewer computational resources.
DeepSeek may have leveraged data from OpenAI, Meta, and Google models. Ignoring its existence and failing to benefit from it would be unwise. Companies striving for excellence should utilize every available resource, much like they take advantage of information found on the internet, some of which may be protected by copyright.
Did DeepSeek Utilize Distillation, and Is It the Key to Their Model’s Superiority?
It is unlikely that DeepSeek employed distillation in the traditional “teacher-student” sense. Instead, it seems more plausible that they integrated the collected data directly into their model’s training dataset.
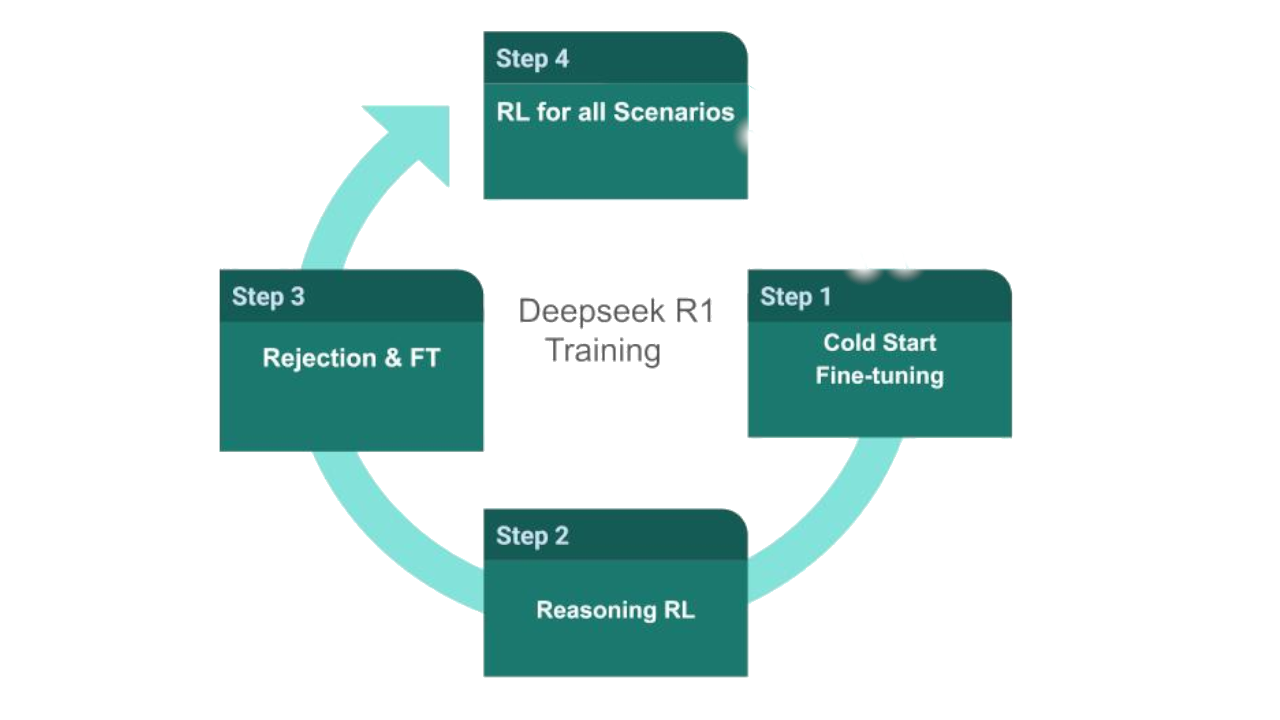
This suggests that DeepSeek has developed a groundbreaking training methodology, incorporating innovations previously unseen in the field. Evidence for this is found both in their research paper and the behavior of their model. For example, the model clearly articulates its self-reflection process with precise language, a feature not present in other models. This indicates the use of reinforcement learning with a unique reward mechanism, highlighting another potential innovation
Moreover, even if DeepSeek did employ distillation, the result should not be a model that outperforms the “teacher.” If such an outcome were to occur, it would necessitate a critical reevaluation of the “teacher” model’s design, suggesting that it was likely suboptimal.
How can OpenAI respond to the challenge posed by DeepSeek-R1?
I believe OpenAI can adopt several strategic measures to effectively respond to the rise of DeepSeek R1.
Firstly, OpenAI should capitalize on the open-source nature of DeepSeek’s technology. This approach allows them to generate new training data for their models without facing legal scrutiny.
Secondly, OpenAI must focus on developing superior AI models by innovating in architecture, training methodologies, and cost-efficiency. For example, Mark Zuckerberg has reportedly established four dedicated “war rooms” at Meta to investigate DeepSeek’s efficient training process. OpenAI should consider forming similar teams to analyze how DeepSeek achieved such remarkable results at a lower cost. This analysis is in OpenAI’s best interest, as discovering more economical development approaches could unlock significant potential. By leveraging their substantial resources and funding, OpenAI can accelerate innovation, explore new domains, and maintain industry leadership.
While OpenAI’s advancements have been expensive, the foundation of their success lies in innovation, not merely in the consumption of costly resources. This focus on innovation must be reaffirmed.
By taking these steps, OpenAI can not only respond effectively to DeepSeek’s challenge but also reinforce their commitment to pioneering cutting-edge AI technologies.