DeepSeek’s exceptional performance is fueled by its integration of the Mixture-of-Experts (MoE) architecture with a cutting-edge multi-step training approach, combining reinforcement learning (RL) and supervised fine-tuning.
The MoE architecture optimizes efficiency by dynamically activating only the necessary subset of its vast parameter set for each input token, while the RL training approach empowers models to independently learn sophisticated reasoning skills.
Post-Training approach
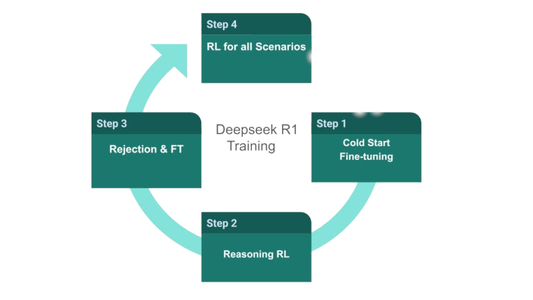
DeepSeek R1’s post-training process utilizes a multi-stage approach, integrating reinforcement learning (RL) with supervised fine-tuning. Here’s the steps:
1- Cold Start Fine-tuning:
Cold Start Fine-tuning begins by collecting a small dataset of high-quality examples featuring long, well-formatted Chain-of-Thought (CoT) reasoning, such as those found in mathematics or coding problems, consisting of the question and the answer presented in multiple steps. This dataset is then used to fine-tune the pre-trained DeepSeek-V3-Base model, enhancing its initial capacity to generate readable and structured reasoning.
2- Reasoning-Oriented Reinforcement Learning (RL):
This step involves training the fine-tuned model on the Cold Start dataset to enhance its reasoning capabilities. The dataset includes a diverse array of reasoning problems collected from various sources, such as textbooks, online repositories, and coding platforms.
The fine-tuned model generates responses to these problems, and a reward system evaluates each response based on three criteria:
- Accuracy: The correctness of the final answer.
- Format: The readability of the reasoning process, using <think> tags to show the reasoning steps.
- Language Consistency: Penalizes outputs that mix languages to ensure the model produces clear and readable reasoning steps.
The process employs Group Relative Policy Optimization (GRPO), which assesses various responses from the model to the same question and calculates their advantage relative to the group’s average reward. This method encourages the model to generate more suitable responses without requiring annotated examples.
3- Rejection Sampling and Supervised Fine-tuning:
Rejection sampling is used to select high-quality responses (e.g., correct, well-formatted, and free of language mixing) from a large number of outputs generated by the RL-trained model, which are then combined with existing supervised fine-tuning data from other domains (writing, factual QA, etc.) to fine-tune the model further.
4- Reinforcement Learning for All Scenarios:
A secondary RL stage refines the model’s behavior by leveraging a diverse set of rewards. This includes reasoning-specific rewards for tasks with clear rules, like math or coding, and human preference rewards to align the model with values such as helpfulness and harmlessness. Additionally, the model is trained on a wide variety of prompts to enhance its generalizability
This multi-stage process allows DeepSeek R1 to leverage the power of both supervised learning and reinforcement learning, resulting in a model with strong reasoning capabilities, improved readability, and better alignment with human preferences.